海安幼儿园 白丝 OpenAI职工任意泄露:里面已收效开发ASI?被曝训出GPT-5但雪藏

裁剪:Aeneas KingHZ海安幼儿园 白丝
【新智元导读】OpenAI,有大事发生!最近多样爆料频出,比如OpenAI依然跨过「递归自我纠正」临界点,o4、o5依然能自动化AI研发,致使OpenAI依然研发出GPT-5?OpenAI职工如潮流般爆料,任意泄露里面已开发出ASI。
各种迹象标明,最近OpenAI似乎发生了什么大事。
AI辩论员Gwern Branwen发布了一篇对于OpenAI o3、o4、o5的著作。
凭证他的说法,OpenAI依然逾越了临界点,达到了「递归自我纠正」的门槛——o4或o5能自动化AI研发,完成剩下的使命!

著作重点如下——
- OpenAI可能礼聘将其「o1-pro」模子守秘,诳骗其缱绻资源来老师o3这类更高档的模子,访佛于Anthorpic的计谋
- OpenAI可能信赖他们依然在AI发展方面取得了冲破,正在走向ASI之路
- 方针是开发一种运行效果高的超东说念主AI,访佛于AlphaGo/Zero所达成的方针
- 推理时搜索最初不错提高性能,但最终会达到极限
致使还出现了这么一种传言:OpenAI和Anthropic依然老师出了GPT-5级别的模子,但都礼聘了「雪藏」。
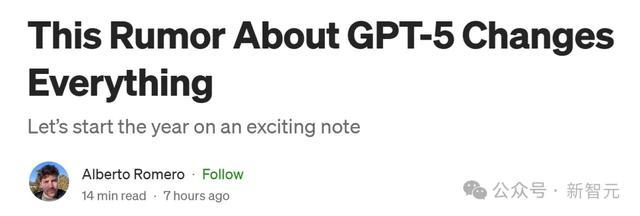
原因在于,模子虽才调强,但运营资本太高,用GPT-5蒸馏出GPT-4o、o1、o3这类模子,才更具性价比。
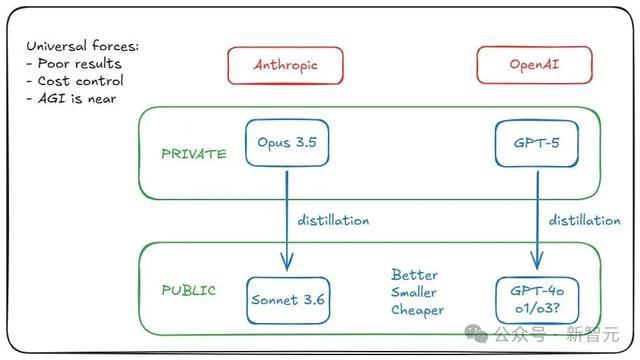
致使,OpenAI安全辩论员Stephen McAleer最近两周的推文,看起来简直跟短篇科幻演义相通——
我有点怀念畴昔作念AI辩论的时候,其时咱们还不知说念若何创造超等智能。
在前沿实验室,许多辩论东说念主员都尽头精致地对待AI短时辰的影响,而实验室除外简直莫得东说念主充分究诘其安全影响。
而当今范围超等智能依然是近在面前的辩论事项了。
咱们该若何范围阴谋多端的超等智能?即使领有完整的监视器,难说念它不会劝服咱们将其从沙箱中开释出来吗?
总之,越来越多OpenAI职工,都开动泄露他们依然在里面开发了ASI。
这是竟然吗?如故CEO奥特曼「谜语东说念主」的作风被底下职工学会了?

好多东说念主合计,这是OpenAI惯常的一种炒作妙技。

但让东说念主有点发怵的是,有些一两年前离开的东说念主,其实抒发过担忧。
莫非,咱们竟然已处于ASI的边缘?

超等智能(superintelligence)的「潘多拉魔盒」,竟然被翻开了?
OpenIAI:「遥遥最初」
OpenAI的o1和o3模子,开启了新的膨大范式:在运行时对模子推理进入更多缱绻资源,不错踏实地提高模子性能。
如底下所示,o1的AIME准确率,跟着测试时缱绻资源的对数加多而呈恒定增长。
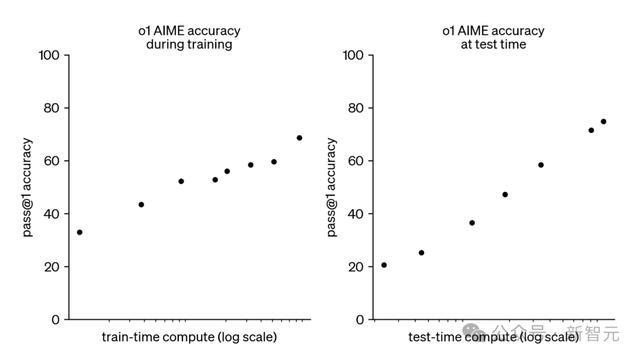
OpenAI的o3模子延续了这一趋势,创造了破记载的证据,具体收货如下:
在Codeforces上得分2727,使其成为寰球第175名最优秀的竞技编程者;
在FrontierMath上得分25%海安幼儿园 白丝,该平台的「每个问题都需要数学家几个小时的使命」;
在GPQA上得分88%,其中70%的分数代表博士级别的科学常识;
在ARC-AGI上得分88%,而在艰苦的视觉推理问题上,平均Mechanical Turk东说念主工任务工东说念主的得分为75%。
凭证OpenAI的说法,o系列模子的性能提高主要来自于加多想维链(Chain-of-Thought,CoT)的长度(以过火他手艺,如想维树),并通过强化学习纠正想维链(CoT)经过。
咫尺,运行o3在最大性能下尽头不菲,单个ARC-AGI任务的资本约为300好意思元,但推理资本正以每年约10倍的速率下落!
Epoch AI的一项最新分析指出,前沿实验室在模子老师和推理上的浪费可能相似。
因此海安幼儿园 白丝,除非接近推理膨大的硬性遗弃,不然前沿实验室将继续多数进入资源优化模子推理,何况资本将继续下落。
就一般情况而言,推理膨大范式瞻望可能会握续下去,何况将是AGI安全性的一个关节有计划要素。
AI安全性影响
那么推理膨大范式对AI安全性的影响是什么呢?简而言之,AI安全辩论东说念主员Ryan Kidd博士认为:
AGI时辰表大体不变,但可能会提前一年。
对于前沿模子的部署,可能会减少其过度部署的影响,因为它们的部署资本将比预期高出约1000倍,这将减少来骄贵速或集体超等智能的近期风险。
想维链(CoT)的监督可能更有用,前提是辞让非谈话的CoT,这对AI安全性有益。
更小的、运行资本更高的模子更容易被盗用,但除非尽头蹧跶,不然很难进行操作,这减少了单边主义黑白的风险。
膨大可发挥性更容易如故更难;尚不信服。
模子可能会更多地接纳强化学习(RL),但这将主若是「基于经过」的,因此可能更安全,前提是辞让非谈话的CoT。
出口料理可能需要退换,以应酬专用推理硬件。
AGI时辰表
o1和o3的发布,对AGI时辰表的预测的影响并不大。
Metaculus的「强AGI」预测似乎因为o3的发布而提前了一年,瞻望在2031年中期达成;但是,自2023年3月以来,该预测一直在2031到2033年之间波动。
Manifold Market的「AGI何时到来?」也提前了一年,从2030年退换为2029年,但最近这一预测也在波动。
很有可能,这些预测平台依然在某种进程上有计划了推理缱绻膨大的影响,因为想维链并不是一项新手艺,即使通过RL增强。
总体来说,Ryan Kidd认为他也莫得比这些预测平台现时预测更好的观念。
人体艺术部署问题
在《AI Could Defeat All Of Us Combined》中,Holden Karnofsky形色了一种滞滞泥泥的风险挟制模子。
在此模子中,一群东说念主类水平的AI,凭借更快的贯通速率和更好的献媚才调越过了东说念主类,而非依赖于定性上的超等智能才调。
这个情景的前提是,「一朝第一个东说念主类水平的AI系统被创造出来,创造它的东说念主,不错诳骗创造它所需要的疏通缱绻才调,运行数亿个副本,每个副本粗略运行一年。」
如果第一个AGI的运行资本和o3-high的资本相通(约3000好意思元/任务),总资本至少要3000亿好意思元,那么这个挟制模子似乎就不那么实在了。
因此,Ryan Kidd博士对「部署问题」问题的担忧较小,即一朝经过不菲的老师,短期模子就不错低价地部署,从而产生普遍影响。
这在一定进程上松开了他对「集体」或「高速」超等智能的担忧,同期稍许提高了对「定性」超等智能的和顺,至少对于第一代AGI系统而言。
监督想维链
如果模子的更多贯通,所以东说念主类可发挥的想维链(CoT)神气镶嵌,而非里面激活,这似乎是通过监督来促进AI安全性的好音问!
尽管CoT对模子推理的形色并不老是真实或准确,但这极少可能得到纠正。
Ryan Kidd也对LLM接济的红队成员握乐不雅立场,他们粗略详实避讳的无餍,或者至少遗弃可能机密执行的决策的复杂度,前提是有强有劲的AI范围次第
从这个角度来看,推理缱绻膨大范式似乎尽头有益于AI安全,前提是有弥散的CoT监督。
祸殃的是,像Meta的Coconut(「连气儿想维链」)这么的手艺可能很快就会应用于前沿模子,连气儿推理不错不使用谈话动作中介景况。
尽管这些手艺可能带来性能上的上风,但它们可能会在AI安全性上带来普遍的隐患。
正如Marius Hobbhahn所说:「如果为了轻微的性能提高,而阵一火了可读的CoT,那简直是在自毁前景。」
但是,有计划到用户看不到o1的CoT,尚不信服是否能知说念非谈话CoT被部署的可能性,除非通过抵挡性错误揭示这极少。
AGI来了
好意思国AI作者和辩论员Gwern Branwen,则认为Ryan Kidd遗漏了一个迫切方面:像o1这么的模子的主要办法之一不是将其部署,而是生成下一个模子的老师数据。
o1措置的每一个问题当今都是o3的一个老师数据点(举例,任何一个o1会话最终找到正确谜底的例子,都来老师更缜密的直观)。
这意味着这里的膨大范式,可能最终看起来很像现时的老师时范式:多数的大型数据中心,在英勇老师一个领有最高智能的最终前沿模子,并以低搜索的形势使用,何况会被转化为更小更便宜的模子,用于那些低搜索或无搜索的用例。
对于这些大型数据中心来说,使命负载可能简直都备与搜索有关(因为与实质的微调比拟,推出模子的资本便宜且浅易),但这对其他东说念主来说并不迫切;就像之前相通,所看到的基本是,使用高端GPU和多数电力,恭候3到6个月,最终一个更智能的AI出现。
OpenAI部署了o1-pro,而不是将其保握为特有,并将缱绻资源投资于更多的o3老师等自举经过。
Gwern Branwen对此有点诧异。
明显,访佛的事情也发生在Anthropic和Claude-3.6-opus上——它并莫得「失败」,他们只是礼聘将其保握为特有,并将其蒸馏成一个小而便宜、但又奇怪地机灵的Claude-3.6-sonnet。)
OpenAI冲破「临界点」
OpenAI的成员倏得在Twitter上变得有些奇怪、致使有些喜不自禁,原因可能即是看到从原始4o模子到o3(以及当今的景况)的纠正。
这就像不雅看AlphaGo在围棋中等海外名次:它一直在飞腾……飞腾……再飞腾……
可能他们合计我方「冲破了」,终于跨过了临界点:从单纯的前沿AI使命,简直每个东说念主几年后都会复制的那种,逾越到升起阶段——破解了智能的关节,以至o4或o5将粗略自动化AI研发,并完成剩下的部分。
2024年11月,Altman泄露:
我不错看到一条旅途,咱们正在作念的使命会继续加快增长,畴昔三年取得的进展将继续在将来三年、六年、九年或更永劫辰里继续下去。
不久却又改口:
咱们当今尽头确信地知说念若何构建传统预料上的AGI……咱们开动将方针超越这极少,迈向实在预料上的超等智能。咱们很可爱咱们咫尺的居品,但咱们是为了好意思好的将来。通过超等智能,咱们不错作念任何事情。
而其他AI实验室却只可莫可奈何:当超等智能辩论粗略自食其力时,根蒂无法赢得所需的大型缱绻拓荒来竞争。
最终OpenAI可能吃下通盘AI市集。
毕竟AlphaGo/Zero模子不仅远超东说念主类,而且运行资本也尽头低。只是搜索几步就能达到超东说念主类的实力;即使是只是前向传递,已接近奇迹东说念主类的水平!
如果看一下下文中的有关膨大弧线,会发现原因其实不言而喻。

论文流畅:https://arxiv.org/pdf/2104.03113
继续蒸馏
推理时的搜索就像是一种刺激剂,能立即提高分数,但很快就会达到极限。
很快,你必须使用更智能的模子来改善搜索自己,而不是作念更多的搜索。
如果单纯的搜索能如斯有用,那海外象棋在1960年代就能措置了.
而实质上,到1997年5月,缱绻机才打败了海外象棋天下冠军,但越过海外象棋群众的搜索速率并不难。
如果你想要写着「Hello World」的文本,一群在打字机上的山公可能就弥散了;但如果想要在寰宇毁掉之前,得到《哈姆雷特》的全文,你最佳当今就开动去克隆莎士比亚。
运道的是,如果你手头有需要的老师数据和模子,那不错用来创建一个更机灵的模子:机灵到不错写出失色致使超越莎士比亚的作品。
2024年12月20日,奥特曼强调:
在今天的噪声中,似乎有些音问被忽略了:
在编程任务中,o3-mini将越过o1的证据,而且资本还要少好多!
我瞻望这一趋势将握续下去,但也料猜度为赢得角落的更多性能而付出指数级加多的资金,这将变得尽头奇怪。
因此,你不错费钱来改善模子在某些输出上的证据……但「你」可能是「AI 实验室」,你只是费钱去改善模子自己,而不单是是为了某个一般问题的临时输出。
这意味着外部东说念主员可能永恒看不到中间模子(就像围棋玩家无法看到AlphaZero老师经过中第三步的随即查验点)。
而且,如果「部署资本是当今的1000倍」建立,这亦然不部署的一个情理。
为什么要浪费这些缱绻资源来就业外部客户,而不继续老师,将其蒸馏且归,最终部署一个资本为100倍、然后10倍、1倍,致使低于1倍的更优模子呢?
因此,一朝有计划到所有这个词的二阶效应和新使命流,搜索/测试时辰范式可能会看起来突出地闇练。